Les facteurs et classes (discrétisation)
Nous allons maintenant aborder un peu plus les variables catégorielles et la mise en classe (genre quand on met "petit", "moyen", "grand").
Les facteurs
C'est un type d'objet dont je n'ai pas encore parlé, ce n'est pas de la méchanceté, j'attendais simplement de pouvoir l'associer à quelque chose de concret sans avoir à le faire sonner deux fois (tout ça pour ça, j'assume).
Un facteur est un élément central dans une étude statistique, il s'agit simplement d'une variable catégorielle. Alors je vous entends d'ici (oui, mon ouïe surdéveloppée traverse aussi le temps) : "Eh mec, pourquoi le texte seul, en chaînes de caractères, ça suffit pas ?!". Déjà, tu me connais pas, tu m'appelles pas mec, c'est très mal élevé... Ensuite, le problème d'une chaîne est que le texte est libre, donc on risque de ne pas noter exactement la même chose (fautes de frappe ou des fois, on nomme la même chose de deux façons un peu différentes  ). Dans les bases de données ou les formulaires, on met des menus déroulants avec des listes pré-établies pour éviter ça, les facteurs, c'est un peu la même idée.
). Dans les bases de données ou les formulaires, on met des menus déroulants avec des listes pré-établies pour éviter ça, les facteurs, c'est un peu la même idée.
Les facteurs sont donc une liste de termes pré-établie (que l'on peut évidement faire évoluer dans le temps) ET il possèdent un ordre. Ça, c'est très pratique, pas besoin de revenir manuellement sur l'ordre d'apparition des éléments dans un tableau ou un graphique parce que le logiciel range toujours tout dans l'ordre alphabétique ... 
Je vous propose de reprendre la liste des interprétations et des datations pour les mettre en vecteur.
Pour créer un facteur, une fonction levels(). On peut soit réécrire la colonne (interpretation <- factor(c("fosse","fosse","trou de poteau","trou de poteau","fosse","trou de poteau","trou de poteau", "trou de poteau"))), soit, pour fait plus simple, écrire la ligne sur elle-même :
liste_US$interpretation <- factor(liste_US$interpretation)
On fait pareil pour les datations :
liste_US$datation <- factor(liste_US$datation)
Et maintenant, str() et summary() sur nos deux colonnes :
summary(liste_US[, c(2,5)])
# interpretation datation
# fosse :3 XVe s. :3
# trou de poteau:5 XVIe-XVIIe s.:5
#str(liste_US[, c(2,5)])
#'data.frame': 8 obs. of 2 variables:
# $ interpretation: Factor w/ 2 levels "fosse","trou de poteau": 1 1 2 2 1 2 2 2
# $ datation : Factor w/ 2 levels "XVe s.","XVIe-XVIIe s.": 2 2 1 2 2 2 1 1
Summary() nous donne maintenant directement le nombre d'occurrence pour chaque terme et str() nous indique bien "factor", puis le nombre de niveau (le nombre de termes différents qui le compose), suivi des termes eux-même dans leur ordre.
Pour modifier ou un élément dans un vecteur de facteurs, la fonction levels() :
levels(liste_US$datation) <- c("XVe s.","XVIe-XVIIe s.","XIIIe s.")
Attention, la position des facteurs dans le vecteur compte. Si on écrit une période, genre "XIIIe s." premier (parce qu'a priori, c'est situé avant le XVe s. (enfin je dis ça, rien n'est moins sûr)), on va remplacer le premier terme ("XVe s." dans noter vecteur) et tous les "XVe s." seront remplacés par "XIIIe s." (c'est quand même ballot). Le plus simple est de réordonner le vecteur après coup, toujours avec levels(), mais imbriqué dans une fonction factor() :
liste_US$datation = factor(liste_US$datation, levels = c("XIIIe s.", "XVe s.","XVIe-XVIIe s."), ordered = TRUE)
Les facteurs possèdent évidemment bien d'autres propriétés, nous aurons pleinement l'occasion de les explorer dans nos pérégrinations futures.
La mise en classe
Il existe plusieurs façons de classer ses données dans R, ici, nous nous limiterons aux méthodes les plus basiques, en fonction du type de la variable à traiter, textuelle ou numérique.
Variable numérique, la fonction cut
Alors, comment discrétiser une donnée ? Discrétiser, c'est (très rapidement) transformer une variable continue (comme des mesures) en classe, par pas. Vous voyez, c'est comme quand on dit qu'on peut transformer une variable quantitative en qualitative, mais pas l'inverse. Autre exemple, c'est ce que nous faisons quand nous réalisons un histogramme. Pour des artefacts, c'est quand on met ensemble tous ceux qui mesurent entre 0 et 5 cm, puis un deuxième groupe de 5 à 10, puis un troisième de 10 à 15, etc. On va travailler sur notre exmple des US (même s'il n'a pas beaucoup de données, mais ça ira pour l'exemple).
Notre but, ici, est d'indiquer dans une nouvelle colonne si notre US est courte, moyenne ou longue en fonction de la variable long.cm. La fonction que nous allons utiliser est cut() et fonctionne basiquement comme ça : cut(données, ruptures, nom des classes). Pour les ruptures, vous avez le choix, si vous indiquez une seule valeur, cela donnera le nombre de classes selon lequel sera découpée votre population. Pour les étiquettes (ou noms de classes), si vous ne mettez rien, R utilisera les bornes de ces classes :
cut(liste_US$long.cm,3)
#[1] (34.9,66.7] (66.7,98.3] (34.9,66.7] (34.9,66.7] (98.3,130] (34.9,66.7] (34.9,66.7] (34.9,66.7]
#Levels: (34.9,66.7] (66.7,98.3] (98.3,130]
La première ligne qui nous est retournée est la classe à laquelle correspond chaque individu et la deuxième ligne, le nombre d'éléments du facteur (ici, on en a bien trois). Notez que le découpage en classes est fait selon les valeurs, ici la distance entre la valeur maximale et la valeur maximale est divisée par trois. Pour vérifier ça :
(max(liste_US$long.cm)-min(liste_US$long.cm))/3
#[1] 31.66667
On a bien 31.6 cm d'amplitude pour chaque classe.
Si vous indiquez plusieurs valeurs, il s'agira cette fois des positions des ruptures, Attention, seules les valeurs entre ces bornes sont considérées :
cut(liste_US$long.cm,c(50,100))
#[1] <NA> (50,100] <NA> <NA> <NA> <NA> (50,100] (50,100]
#Levels: (50,100]
Vous avez vu ? Tout ce qui est en-dessous de 50 et au-dessus de 100 a été ignoré, c'est quand même franchement pas cool. C'est comme si on votait et que le premier ministre était choisi dans un groupe minoritaire parce que la plupart des votes ne sont pas considérés (ça serait vraiment fou, non ?!). Alors nous, comme on est sympas, on va considérer tout le monde. Alors attention aussi, par défaut, la borne inférieure n'est pas inclue :
min(liste_US$long.cm)
#[1] 35
max(liste_US$long.cm)
#[1] 130
cut(liste_US$long.cm,c(35,50,100,130))
#[1] (35,50] (50,100] <NA> (35,50] (100,130] (35,50] (50,100] (50,100]
#Levels: (35,50] (50,100] (100,130]
Pour que la troisième valeur soit considérée, soit on déplace notre borne inférieure, soit on modifie l'argument include.lowest = TRUE (qui est en FALSE par défaut). Pour des questions de simplicité et cohérences des données, on va déplacer la borne inférieure :
cut(liste_US$long.cm,c(34,50,100,130))
#[1] (34,50] (50,100] (34,50] (34,50] (100,130] (34,50] (50,100] (50,100]
#Levels: (34,50] (50,100] (100,130]
Cette fois, toutes les données ont été classées, c'est quand même plus sympa !
Et puis, c'est souvent bien pratique, on peut aussi utiliser des fonctions pour ça, moi perso, j'aime bien utiliser seq(). Encore un Attentiont, la fonction seq() ne peut pas dépasser la borne maximum. Donc si vous faites cut(liste_US$long.cm,seq(34,130,10)), ça va s'arrêter à 124 (124+10, ça dépasse 130 donc on ne peut pas atteindre 130 dans ces conditions, ballot). Alors on y prête attention (c'est vraiment LE mot de cette sous-section) :
cut(liste_US$long.cm,seq(34,134,10))
#[1] (44,54] (74,84] (34,44] (34,44] (124,134] (44,54] (44,54] (54,64]
#Levels: (34,44] (44,54] (54,64] (64,74] (74,84] (84,94] (94,104] (104,114] (114,124] (124,134]
#ou
cut(liste_US$long.cm,seq(30,130,10))
#[1] (40,50] (70,80] (30,40] (40,50] (120,130] (40,50] (50,60] (50,60]
#Levels: (30,40] (40,50] (50,60] (60,70] (70,80] (80,90] (90,100] (100,110] (110,120] (120,130]
Pour décider de vos bornes, c'est souvent judicieux de mettre des trucs simples à comprendre. Ici, notre deuxième formule qui va de 10 en 10 en tombant sur des multiples de 10, c'est plutôt pratique, ça parle à tout le monde, basique, simple.
Enfin, pour les étiquettes, il suffit de les indiquer comme un vecteur numérique. De plus, pour cette dernière manipulation, nous allons créer une colonne qui va contenir la classe. Nous pourrons ainsi filtrer et traiter nos données en fonction de notre nouvelle classification :
liste_US$classe.long <- cut(liste_US$long.cm,4,c("petit","moyen","long","très long"))
table(liste_US$classe.long)
# petit moyen long très long
# 5 2 0 1
On a un résultat pertinent avec des classes super utiles.
ifelse
Comme l'a fait remarqué mon moi du passé, les classe obtenues avec nos quatre catégories ne sont pas très pertinentes, surtout pout "long" et "très long". On va les regrouper en "long" (pas très imaginatif, mais on va faire simple). Pour ça, on va à nouveau créer des classes, mais cette fois sur une variable catégorielle. On peut, soit réécrire directement la colonne (plus simple et rapide, mais plus dangereux), soit créer une nouvelle colonne (plus long et complexe, mais BEAUCOUP plus safe  ).
).
On va utiliser une commande qui n'est pas sans nous rapeller les opérateurs logiques et qui existe dans foultitude d'autres envorinnements et langages de programmation, le ifelse (il y aurait un smiley John Cena, je l'aurais mis). Cette commande est GIGA pratique et avec un fonctionnement "simple". Sa struture ifelse(test, valeur si TRUE, valeur si FALSE). Nous, ce que nous voulons faire c'est tester la variable classe.long. Si elle est "long" ou "très long", nous la classerons comme "long" (oui, on a déjà dit que ça manquait d'originalité, mais si je l'avais appelé "pamplemousse", je suis sûr que vous auriez décroché), sinon, nous utilisons la valeur déjà existente. Petite remarque, ifelse() kiffe pas trop les facteur. Pour ça, on va lui demander de traiter notre variable en facteur comme si c'était du texte pour ensuite la re-convertir en facteur (j'ai dit que c'était pas évident) :
liste_US$classe.long.rec <- ifelse(liste_US$classe.long %in% c("long","très long"), "long",as.character(liste_US$classe.long))
liste_US$classe.long.rec<-factor( liste_US$classe.long.rec)
Les facteurs et mises en classes en plus facile (avec interface graphique)
Pour une manipulation plus aisée, il existe un petit addin bien chouette pour faire vos mises en classe et vos gestion des facteurs. Le package questionr vous fournit tous ces outils. Je vous laisse l'installer et le chercher dans les addins (j'ai expliqué dans une section lointaine comment gérer les packages et les addins).
Là vous avez trois possibilités avec notre nouveau compagnon de traitement de données:
- "Levels recoding" : Pour renommer et ré-encoder des facteurs (et les regrouper aussi)
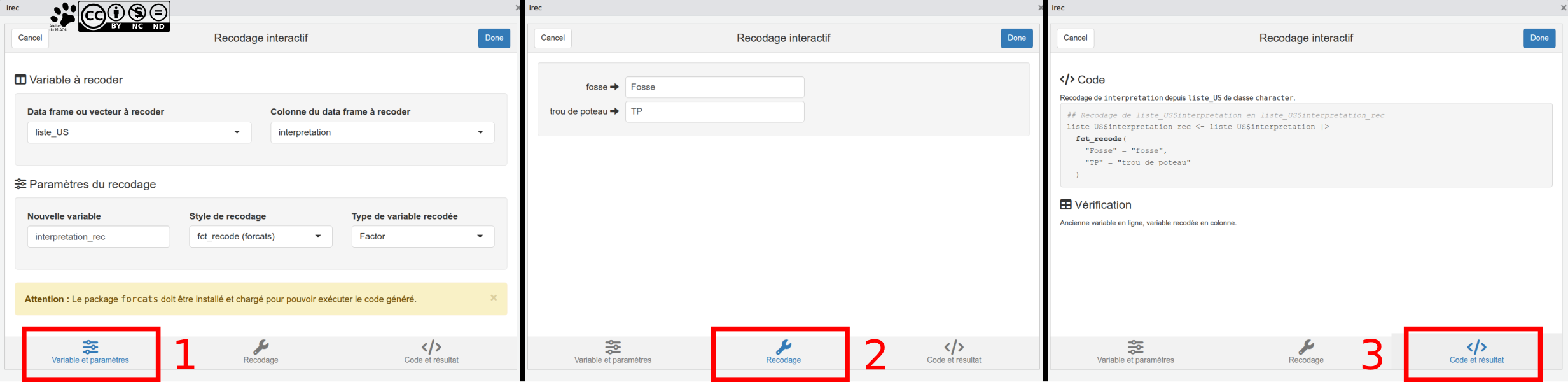
Ça se passe en trois étapes:
- Choisir les données à recoder et comment. Si vous voulez recoder des facteurs, je vous conseille le style "fct_recode" qui vous oblige à installer un nouveau package, mais il vous sera utile plus tard de toute façon. Il faut aussi nommer la colonne dans laquelle la nouvelle organisation de variable sera insérée.
- Choisir comment recoder (là, j'ai fait mininaliste et pas vraiment malin d'ailleurs).
- Génération du code. Comme toujours, c'est plus utile de récupérer le code pour pouvoir l'insérer dans son script que de générer tout de suite des données via la console.
Pour regrouper des facteurs, c'est aussi tout à fait possible avec cette interface, il suffit de leur donner le même nom et, bim, la magie opère ! (c'est aussi pour ça que j'ai pas trop insisté avec ifelse(), même si c'est quand même une commande utile dans plein de cas)
- "Levels ordering" : La façcon la plus simple pour modifier l'ordre des facteurs.
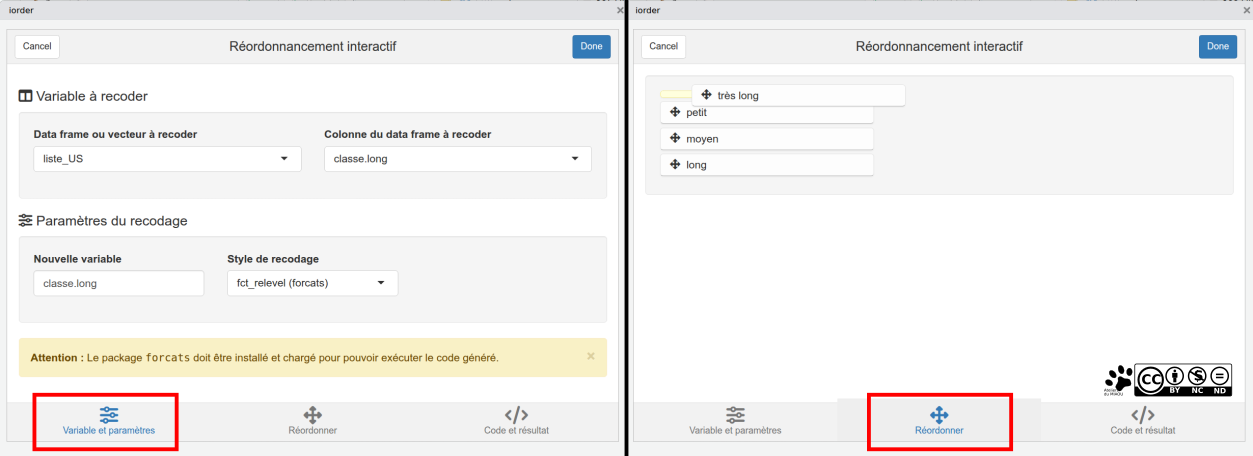
C'est globalement les trois mêmes étapes que précédemment :
- On choisit ses données et sa variables (en favorisant 'forcats')
- On ré-ordonne par un petit "cliquer-glisser-déposer"
On exporte le code (je l'ai pas mis dans la capture d'écran, on a compris je pense).
"Numeric range dividing" : Correspond à la fonction
cutavec plein d'options en plus.
Cette fois, je n'ai mis que la capture d'écrand e l'image centrale. C'est hyper bien fait, avec un petit histogramme interactif. Contrairement à la fonctino cut() que nous avons utiliser nativement, il y a plusieurs méthodes de découpage, je vous laisse les tester. Si vous changez la méthode et que vous allez ensuite observer le code, vous verrez qu'en réalité, c'est l'addin lui-même qui applique les méthodes de découpage différentes pour ensuite, donner uniquement les "breaks" à la fonction cut() de base. C'est bien fait, vous trouvez pas ?