Charger et écrire des données
Encore un point que nous n'avons pas abordé (oui, il y en a forcément beaucoup et comme je change tout le temps l'ordre des sections, bah c'est peut-être le bazar...), c'est comment charger des données (externes ou des jeux de données internes à R) et les exporter ensuite.
Charger un CSV ou un Excel
Le plus simple est d'utiliser un fichier CSV et j'ai la flemme de revenir sur comment tripatouiller un Excel (vous trouverez tout ce dont vous avez besoin sur internet). On va voir comment importer un CSV enregistré vite fait. Je vous propose d'exporter la feuille "inventaire" (un CSV ne peut contenir qu'une seule feuille, donc autant en choisir une pertinente). Faites-le sans vous embêter avec les paramètres d'export (enfin juste pour l'exercice hein ?! Sinon faites quand-même attention ! Il vaut toujours mieux choisir un encodage en UTF-8, un séparateur de champ en , (pensez à remplacer les virgules de vos nombres décimaux par des points) et laissez " en délimiteur de texte). Bon, une fois fait, on l'importe. On va commencer par passer par l'interface graphique.
Dans la fenêtre "Environment", on clique sur "Import dataset" → "From Text (readr)..."
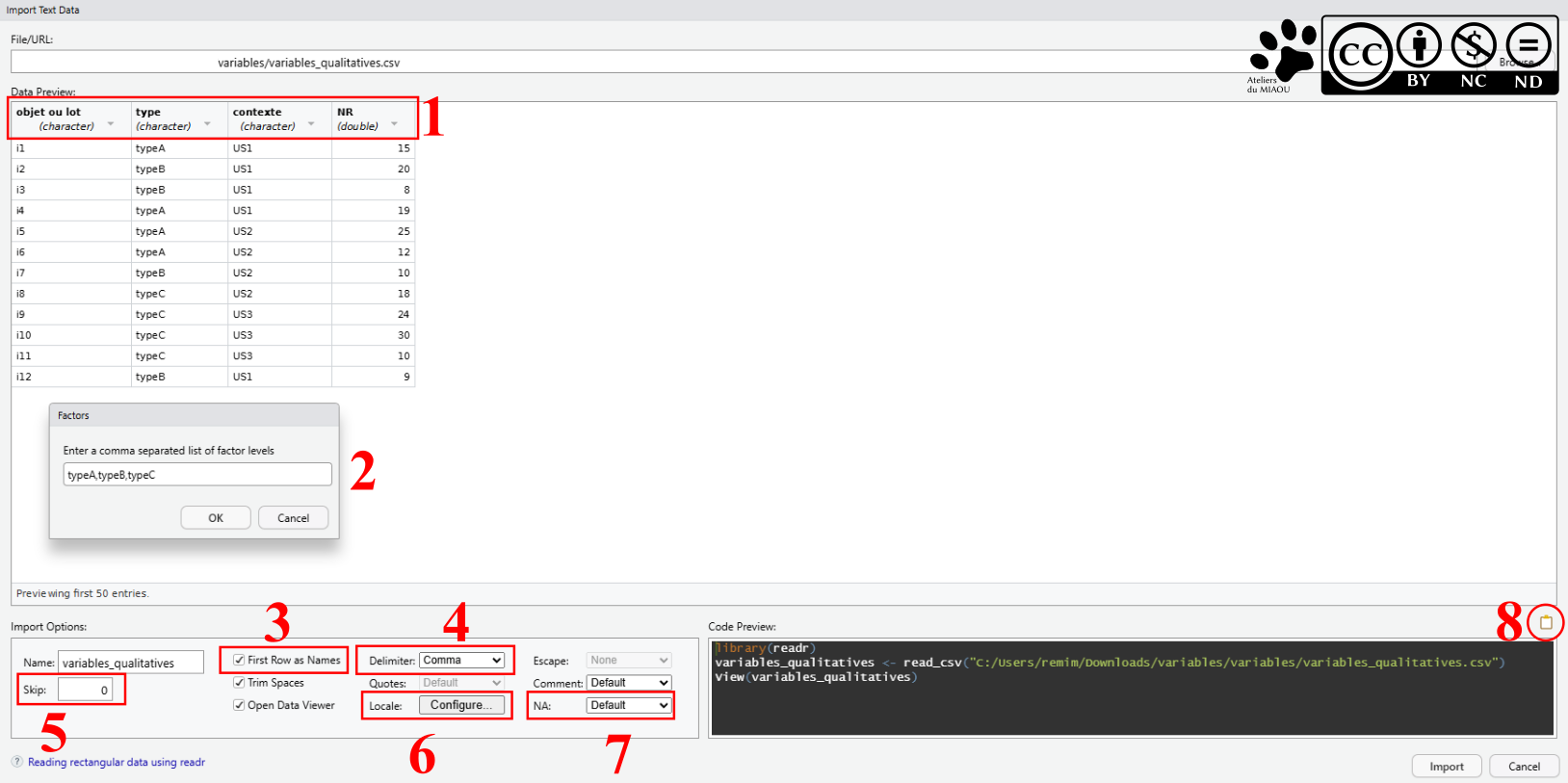
Là, plein de nouveaux trucs (et une capture d'écran que on va dire qu'on peut la lire, mais je suis pas sûr de mon coup...). On va paramétrer notre import pour que tout soit parfait ensuite sous R :
En cliquant sur le nom des colonnes, vous pouvez en désigner le type. Dans notre cas, il est plus utile de modifier la colonne "type", initialement identifiée comme du texte en vecteur.
Ce qui fait que si on la désigne comme vecteur, RStudio nous demande d'écrire les éléments en facteur, ça permet de les avoir dans le bon ordre.
À cocher si la première ligne contient le nom des colonnes.
Normalement, les colonnes du CSV sont séparées par des
,, mais de notre côté de la Terre, ça peut être du;ou autre chose, il faut donc choisir celui qui a été utilisé pour créer le fichier CSV.Il peut y avoir des lignes vides ou utilisées comme en-tête du fichier, on peut les ignorer en détournant le regard sur un nombre déterminé de lignes.
Pour des paramètres supplémentaires (genre on a utilisé des
,comme séparateur décimal), ça se passe là.Je vous ai dit beaucoup plus haut que certains systèmes utilisaient
nullou d'autres trucs pour les valeurs manquantes, bah c'est le moment d'indiquer ce qui a été utilisé.Une fois que tout est fait, ne cliquez pas tout de suite sur import ! Le mieux, c'est de copier le texte que vous pourrez coller dans votre script. Comme ça, si vous modifiez votre CSV, le script rechargera les données, vous traiterez donc un jeu de données mis à jour, c'est quand même chouette ça, non ?
Charger des jeux de données existants
Si vous naviguez sur les océans des internets à la recherche de manipulations et exemples, vous verrez souvent que les manipulations sont données sur des jeux de données qui sont directement chargés dans R, sans avoir besoin de passer par un import complexe. R contient nativement des données d'entraînement et il existe aussi beaucoup de packages qui en contiennent. Dans ce support, nous utiliserons souvent des exemples issus du package archdata. Je vous invite donc à la charger (après installation). Dans sa documentation (si vous cliquez sur le nom du package, ça apparaît directement dans RStudio), vous verrez la liste des exemples contenus. Pour charger des données, c'est la commande data().
library(archdata)
data("BACups")
Et là, vous devriez avoir un nouvel objet qui est apparu dans la fenêtre environnement de RStudio.
Export des données
Là c'est un simple, enfin ici on va se limiter un maximum. Pour le coup, pas d'interface graphique. Une commande basique, write.csv() (il existe évidemment d'autres méthodes d'export, si vous tapez write(en attendant l'autocomplétion), vous verrez plusieurs choix). Avec l'autocomplétion, vous verrez deux modes d'export csv, write.csv() et write.csv2(), ça correspond au séparateur décimal. Le premier utilise le . (recommandé), deuxième utilise la virgule , comme séparateur (pas trop recommandé, à mon sens). Dans sa forme la plus simple, write.csv(données,"données exportées.csv") :
write.csv(liste_US3,"liste_US.csv")
On peut, bien sûr, ajouter des arguments pour modifier l'encodage ou surtout l'emplacement du fichier écrit. Par défaut, le fichier est écrit dans le dossier de travail, c'est simple, c'est pas plus mal. 