Les graphiques
Il est temps de voir maintenant la génération de graphique. On a fait quelques manipulations de données, mais pour l'instant, limitées à nous. C´est nul, si on fait des trucs comme ça, faut pouvoir se la péter avec ! Et quoi de mieux qu'un petit graphique ? Un beau dessin vaudra toujours mieux que deux tu l'auras  .
.
Il existe, évidemment  , plein de façon de générer des graphiques, mais bon, principalement deux (oui, ça casse tout de suite l'effet) :
, plein de façon de générer des graphiques, mais bon, principalement deux (oui, ça casse tout de suite l'effet) :
- les graphiques de base, faciles à générer, mais pas trop sexys.
ggplot(le fameux "ggplot Universe"), un monde que nous explorerons plus tard (mais avec ça, vous gerez des trucs tellement sexys que vous n'aurez même plus besoin de faire de vraie science pour frimer en colloques (c'est l'équivalent du verbiage et des mots clés balancés à tout va qu'utilisent les bullshiters qui font semblant de connaître des trucs)).
Les graphiques de base
On commence par eux parce qu'ils ne sont pas très beaux ou séduisants, mais ils sont toujours là (comme un vieux chien), pratiques (comme un ex) et faciles à générer (euh là...  ).
).
les plots
La fonction plot() est la plus simple et basique pour générer des graphiques. Pour les graphiques qui vont suivre, j'ai réimporté le csv écrit précédemment (liste_US.csv) en l'appelant "liste_US".
(d'ailleurs vous pouvez faire pareil, ça vous donnera l'occasion de pratiquer l'import de données en faisant bien attention de mettre certaines colonnes en texte même si ce sont des nombres, d'importer des champs en facteur et de voir que l'export d'un tableau de données créer des noms de ligne (si vous n'en avez pas mis, comme dans l'exemple de ce support, ça met le numéro de la ligne comme nom
))
Le fonctionnement des plot() est simple, c'est plot(variable en x, variable en y). L'exécution de la commande vous affiche, normalement, un graphique dans la fenêtre prévue à cet effet dans RStudio.
plot(liste_US$long.cm)
Là, je n'ai rien mis en y, donc plot() utilise les positions (leur index) dans le vecteur de la variable pour l'axe y.
On continue avec deux variables (c'est déjà un peu plus intéressant) :
plot(liste_US$long.cm,liste_US$larg.cm)
WOUAOUH !  Ça c'est du graphique ou je ne m'y connais pas !
Ça c'est du graphique ou je ne m'y connais pas !
Bon, il est évident qu'on peut modifier des trucs, les légendes, les couleurs, les symboles, enfin plein de trucs plus fifous les uns que les autres. Certains paramètres sont des arguments que l'on peut insérer directement dans la commande plot(), d'autres correspondent à des commandes différentes qui viennent se superposer au graphique généré (ça n'a pas forcément l'air très clair comme ça, mais ne vous en faites pas, je l'aborde très vite  ).
).
Habillage dans plot() avec arguments
plot() accepte une foultitude d'arguments, vous pouvez aller voir avec help() et vous risquez d'être vite dépassés, tellement une explication renvoie sur une autre, encore et encore (pire que tomber dans un tunnel wikipédia). Je vous en mets dans la commande suivante :
plot(liste_US$long.cm,liste_US$larg.cm,
main = "Rapport entre la largeur et la longueur des structures", # C'est le titre principal du graphique
xlab = "Longueur (en cm)", # Titre de l'axe x
ylab = "Largeur (en cm)", # Titre de l'axe y (oui, c'est fou)
xlim = c(30, 170), # Limites de l'axe x (ça permet de mettre des bornes un peu plus lisibles que celles automatiques)
ylim = c(20, 100), # Limites de l'axe des y (logique)
col = "tomato1" , # Pour mettre de la couleur dans nos vies, tapez `colours()` pour la liste complète. J'ai pris "tomates", ça rappelle l'été
pch = 9, # Choix d'un symbole, `help("points")` vous les indique, certains peuvent faire polémique
cex = 2, # Taille des symboles
#lty = X # Là, c'est le type de ligne (mais comme on a des points)
#lwd = X # La taille des lignes
#type = "X" # Pour choisir un type, "p" pour les points, "l" pour les lignes ou b"" pour les deux. Par exemple, vous pouvez forcer les lignes (pour relier nos points par exemple) type de tracé: points ("p"), lignes ("l"), les deux ("b" ou "o"), ...
)

On obtient tout de même un très beau graphique qui rendra fière la plus exigeante des mamans ! (non, je sais, ça c'est pas vraiment possible) 
Ajouter des éléments avec des fonctions
On peut ajouter des éléments supplémentaires sur lesquels vous pouvez agir plus finement. Je vous mets la liste ici car je ne vais quasiment pas les aborder :
legend(), pour ajouter une légende et la placer là où vous voulez.title(), pour ajouter un titre et le placer là où vous voulez (oui, un petit copier-coller, ça fait jamais de mal).points(), pour rajouter des points, en mettant des coordonnées ou même une fonction. Son fonctionnementpoints(x,y)Pour plusieurs points, une fonction ou des combines :points(c(60,140),c(70,40), col= "blue", pch =8)lines(), pour rajouter (ou "ajouter", vive l'alternance) une polyligne. Il faut mettre les coordonnées et le style comme pour les points, attention, une commande par polyligne :lines(c(40,90,160),c(50,70,30), col= "purple", lwd = 3.4, lty = 6)abline(), ça, c'est pour une ligne droite (genre horizontale, verticale ou qui suit une fonction comme une droite de régression).text(), je vous laisse deviner ce que ça ajoute. Ça fonctionne comme çatext(position x, position y,"texte à afficher"). Un exemple :text(60,90,"ça c'est du graphique de pro !")
Je vous laisse admirer notre oeuvre dont on parlera encore dans des temps immémoriaux  (ouais, on n'a peur de RIEN !)
(ouais, on n'a peur de RIEN !)
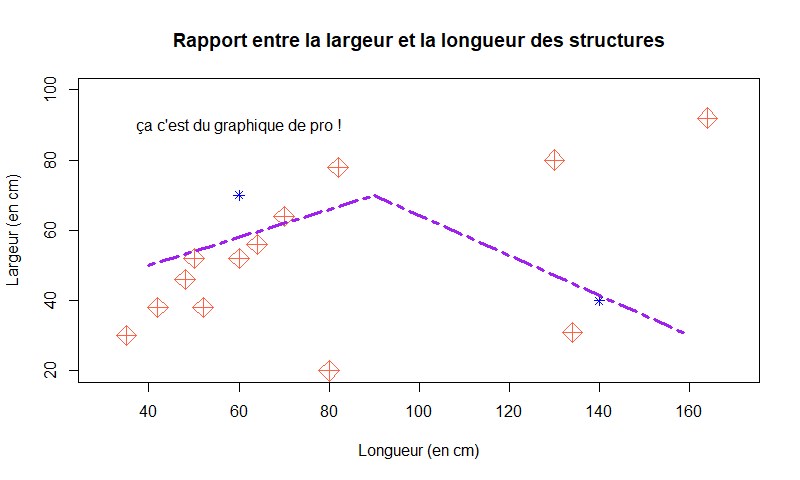

À noter que tous ces éléments viennent se superposer sur le graphique existant, donc si vous faites une erreur et que vous resaisissez votre commande, ça viendra juste l'imprimer d'une autre façon. L'idée, c'est de tester ce qui vous convient sur un brouillon crado et, une fois que tout semble aller, relancer le script depuis la commande plot(), comme ça, tout s'empilera majestueusement.
Distinguer des groupes dans un plot()
Avançons dans notre graphique et poussons plus loin nos interprétations  . Un truc sympa, ça pourrait être, par exemple, de pouvoir distinguer les fosse et les TP (c'est le nom intime d'un trou de poteau). Pour ça, on peut modifier un simple argument, celui de la couleur. Testons en mettant le nom de la variable d'interprétation pour l'argument de la couleur :
. Un truc sympa, ça pourrait être, par exemple, de pouvoir distinguer les fosse et les TP (c'est le nom intime d'un trou de poteau). Pour ça, on peut modifier un simple argument, celui de la couleur. Testons en mettant le nom de la variable d'interprétation pour l'argument de la couleur :
plot(liste_US$long.cm,liste_US$larg.cm,
main = "Rapport entre la largeur et la longueur des structures",
xlab = "Longueur (en cm)",
ylab = "Largeur (en cm)",
xlim = c(30, 170),
ylim = c(20, 100),
col = liste_US$interpretation,
pch = 16,
cex = 2,
)
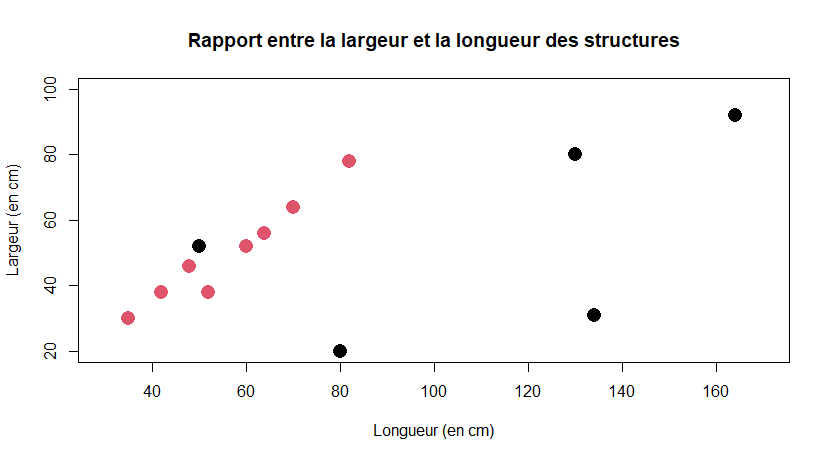
Alors le résultat est pas mal MAIS, vous voyez que rien ne s'affiche en légende et c'est là que la commande legend() entre en scène  (c'est pour faire le projecteur). On va donc rajouter, après
(c'est pour faire le projecteur). On va donc rajouter, après plot().
legend(x = "topleft", title = "Interprétation",legend = levels(liste_US$interpretation) , col = c("black", "red"), pch = 16)
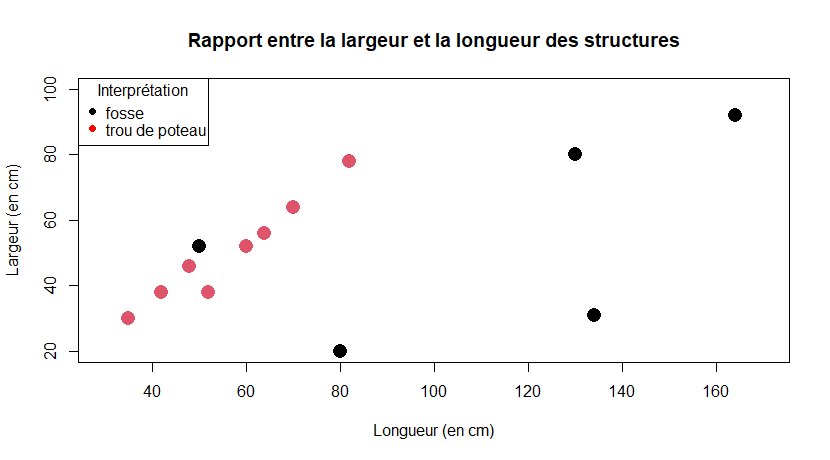
Et là, bim, jolie légende. Bon, c'est pas hyper pratique, mais comme je vous ai dit, les graphiques de base de R, c'est pour du quick and dirty (comme un plan c** ?)
Les autres graphiques de base
D'autres graphiques de base facile et sympa à réaliser sont disponibles. Je vais commencer à les lister sans me prendre la tête, mais bon, je suppose que vous voulez un peu voir comment on fait tout ça  , alors...
, alors...
Les histogrammes
La commande hist() est très utile. Elle permet de créer facilement un histogramme sur une variable continue. C'est la commande elle-même qui se charge de regrouper les classe et compter les individus qui les composent. Un histogramme sur 13 observations, c'est pas folichon (et ça rime !), mais on va faire avec. Dans son utilisation la plus simple, la commande fonctionne comme ça : hist(variable, nombre de classes) ou hist(variable, limites de classe), à noter que pour les limites de classe, on peut aussi mettre une fonction (genre seq() peut s'avérer bien pratique dans cette situation).
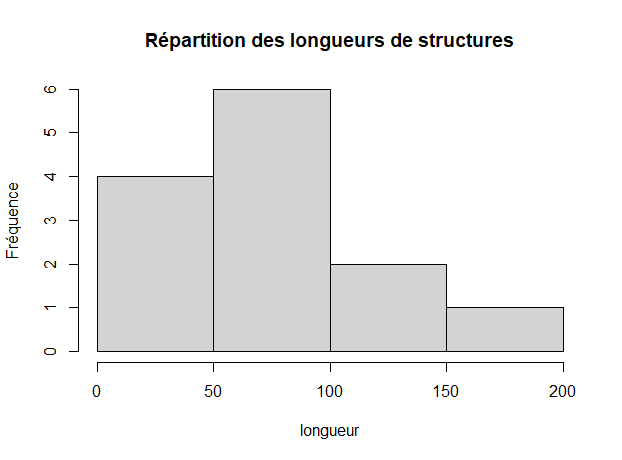
hist(liste_US$long.cm,4, main = "Répartition des longueurs de structures", xlab= "longueur", ylab = "Fréquence")
hist(liste_US$long.cm, c(30,60,90,120,150,180), main = "Répartition des longueurs de structures", xlab= "longueur", ylab = "Fréquence")
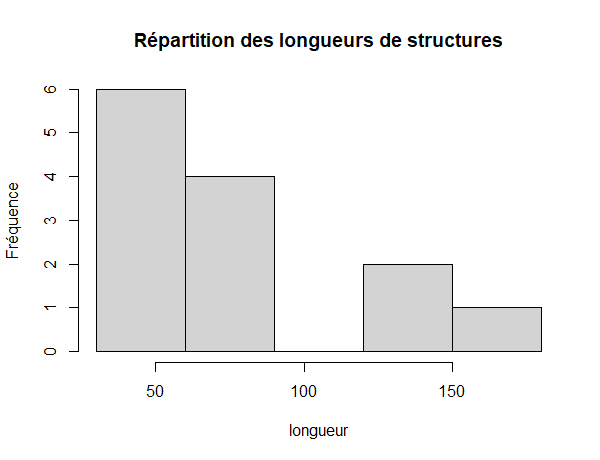
Quand on met des bornes, il faut faire attention à bien englober les valeurs de la variable. Ici, je suis allé de 30 en 30, la fonction seq() peut me faciliter l'écriture :
hist(liste_US$long.cm, seq(30,180,30), main = "Répartition des longueurs de structures", xlab= "longueur", ylab = "Fréquence")
Ça donne le même histogramme, je ne vais donc pas le montrer à nouveau, vous êtes grand.e.s et pouvez aller le voir tout.e seul.e.
Mais maintenant, on peut un peu pimper notre histogramme en lui ajoutant, par exemple, la médiane avec une ligne (je vous avais dit qu'on utiliserait abline()).
abline(v=median(liste_US$long.cm), col = "steelblue", lty = 2, lwd = 2)
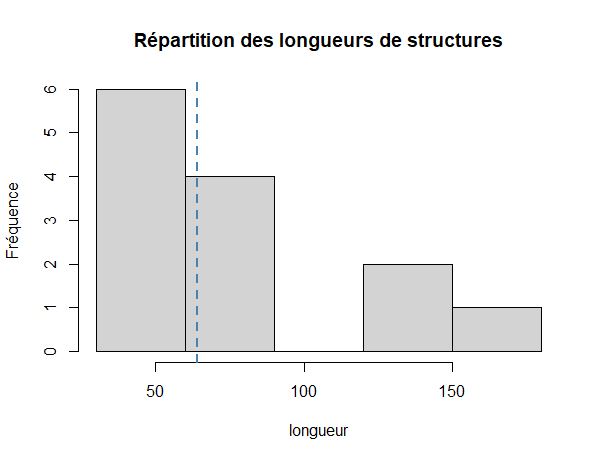
C'est bien beau tout ça 
Boxplot (boîtes à moustache)
La boîte à moustache (whisker box si seulement les anglicisants avait correctement traduit ce terme), c'est une telle tannée à réaliser avec des logiciels de tableur que ça suffit comme raison de se mettre à R.
La fonction boxplot() est giga simple : boxplot(variable, les arguments habituels pour les graphiques de base). Il existe aussi des arguments pour contrôler les outliers (les valeurs extrêmes), je vous laisse aller voir la documentation pour ça.
boxplot(liste_US$long.cm)
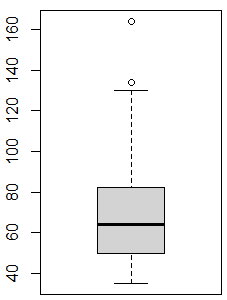
Et les points en haut, ce sont les outliers.
On me l'a demandé donc je rajoute ici l'explication de la façon dont sont déterminés les outliers  . On va commencer avec un
. On va commencer avec un summary() sur notre variable :
summary(liste_US$long.cm)
# Min. 1st Qu. Median Mean 3rd Qu. Max.
# 35.00 50.00 64.00 77.77 82.00 164.00
L'intervalle interquartile, c'est l'étendue entre le premier et le troisième quartile. Sont considérées comme outliers, les valeurs qui sont inférieures au premier quartile ou supérieures au troisième avec une distance de 1,5 fois l'intervalle interquartile. Dans notre cas, l'intervalle interquartile, c'est 82 - 50 = 32 et 1.5*32 = 48. Donc si une valeur est supérieure à au troisième quartile (82) plus 48 (ce qui fait 130), alors elle sera considérée comme outlier. La même chose pour les valeurs inférieures à 50 (le premier quartile) moins 48, donc 2.
sum(liste_US$long.cm > 130)
#[1] 2
sum(liste_US$long.cm < 2)
#[1] 0
On est bon, le diagramme ne montre que deux outliers en haut et aucun en bas ! 
Les diagrammes en barre
Je ne vais pas m'étendre avec des exemples, c'est toujours la même rengaine. Les diagrammes en barre, c'est surtout utile quand vous avez déjà mis vos données en classes (comme on l'a vu avec la fonction cut()) et sur votre tableau de données que vous avez vous-même réorganisé, vous ne pouvez plus utiliser la fonction hist() (vous ne voulez pas qu'il vous recrée des classes). Dans ce cas, utilisez directement barplot().
La tilde ~, graphiques avec groupes
Il est possible de grouper ou visuellement séparer des données en fonction d'un paramètre supplémentaire, comme un facteur. Par exemple, dans notre cas, ça pourrait être chouette  (j'ai trouvé que ça comme oiseau) de distinguer les périodes de datations.
(j'ai trouvé que ça comme oiseau) de distinguer les périodes de datations.
Pour ça, la tilde ~. On la reverra plus tard dans les traitement de données, mais on peut d'ores et déjà dire qu'elle est utilisée pour observer une variable par rapport à une autre (du bivarié directionnel quoi). Elle est utilisé pour écrire des formules. Donc, en général, quand on indique dans R qu'on va utiliser une formule, il faut penser ~ et position spécifique des valeurs. Son écriture est variable observée ~ variable par rapport à laquelle on l'observe. Pour tenter d'être un peu plus clair, dans notre précédent graphique, nous avions les longueurs en absice (en x) et les largeurs en ordonnées (y). La lecture logique de ce graphique, c'est qu'on observe les largeurs par rapport aux longueurs, on observe y par rapport à x.
D'un point de vue pratique, cela implique que pour un tableau dans lequel vous indiquez d'abord x puis y, la formule correspondante, c'est y ~ x. On va bientôt voir que ça a des implications assez concrètes. En attendant
Reprenons donc notre boîte à moustache en différenciant bien les périodes :
boxplot(liste_US$long.cm ~ liste_US$datation)
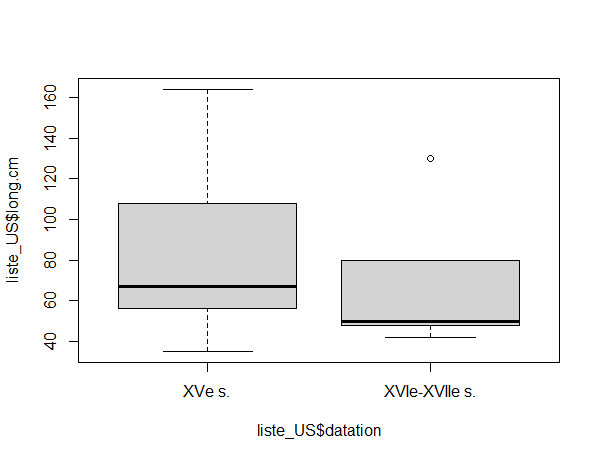
En vrai, c'est quand même giga cool ! 
ggplot(), des graphiques qui ont la classe
ggplot(), c'est un univers ! Hors blagues et lieux communs, c'est quasiment un environnement complet qui va vous permettre de générer des graphiques de folie parfaitement publiables. Il y a un hic  , c'est que ça ne fonctionne pas sur les tableaux croisés ou de contingence. Si vous devez le faire, il y a des méthodes que j'aborderai peut-être un peu plus tard (mais pas sûr (il faut que j'ai le temps (et que je n'oublie pas non plus))). Dans les sous-sections qui suivent, on va d'abord voir comment on utilise
, c'est que ça ne fonctionne pas sur les tableaux croisés ou de contingence. Si vous devez le faire, il y a des méthodes que j'aborderai peut-être un peu plus tard (mais pas sûr (il faut que j'ai le temps (et que je n'oublie pas non plus))). Dans les sous-sections qui suivent, on va d'abord voir comment on utilise ggplot à la main (faut un peu les mettre dans le cambouis pour comprendre comment ça fonctionne), mais je vous rassure, on ira ensuite explorer un petit plugin (ou "addin", c'est pareil) qui va beaucoup nous aider.
la library ggplot2
Vous avez un petit pdf intégré à R Studio qui vous donne des indications pour créer vos graphiques en vous rappelant la grammaire et la syntaxe ggplot, elle est à côté des autres tchitchits ("Cheat Sheets") : "Help" → "Cheat Sheets" → "Data Visualization with ggplot2". Alors oui, le pdf est pas lisible de ouf, mais déjà il existe. Ce qui est certain, c'est qu'ils n'ont pas suivi les recommandations de Bertin, les fous !
Alors oui, je parle de ggplot() alors que la librairie (ou package, paquet, c'est égal) s'appelle ggplot2, ce n'est pas que j'ai (déjà et trop) bu. J'insiste dessus pour ne pas que vous vous trompiez en chargeant la librairie au début de votre script. La commande, en revanche, c'est bien ggplot().
L'organisation globale de ggplot, c'est ggplot(tableau de données, aes(variable en x, variable en y *(si nécessaire)* ), *d'autre paramètres comme le type de statistiques, tout ça (si nécessaire)*) et puis ensuite, vous pouvez ajouter des trucs supplémentaires sous forme de commande avec +, genre : + commande du type de graphique() + commande de style(), etc. Un exemple pour démystifier tout ça :
ggplot(liste_US,aes(long.cm,interpretation)) + geom_violin() + theme_bw()
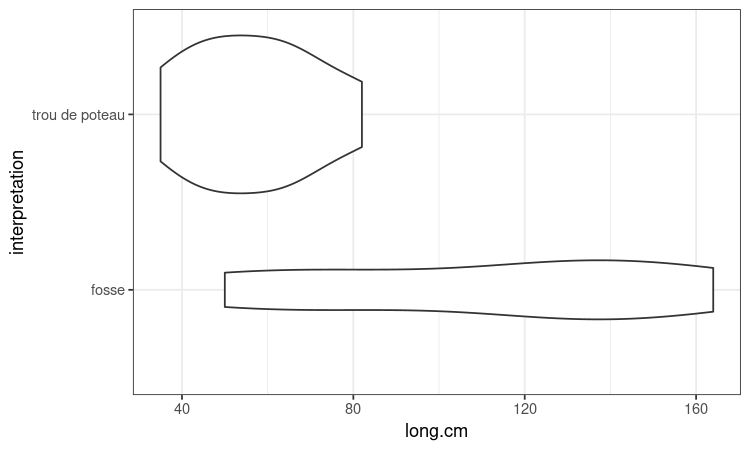
Là, j'ai fait au plus simple avec le minimum de paramètres. Je vous laisse vous référer à la tchitchits et tester plein de trucs. Je ne vais tout de même pas vous laisser sur votre faim avec graphique pas fifou (oui, c'est pas gentil de dire ça, mais des fois il faut reconnaître quand nos créations et nos enfants sont esthétiquement ratés  ).
).
ggplot(liste_US, aes(x = long.cm, y = interpretation, fill = interpretation)) +
geom_boxplot() +
labs(
x = "Distribution des longueurs",
y = "Type de structure",
title = "Longueurs des structures",
fill = "Interprétation"
) +
theme_bw()
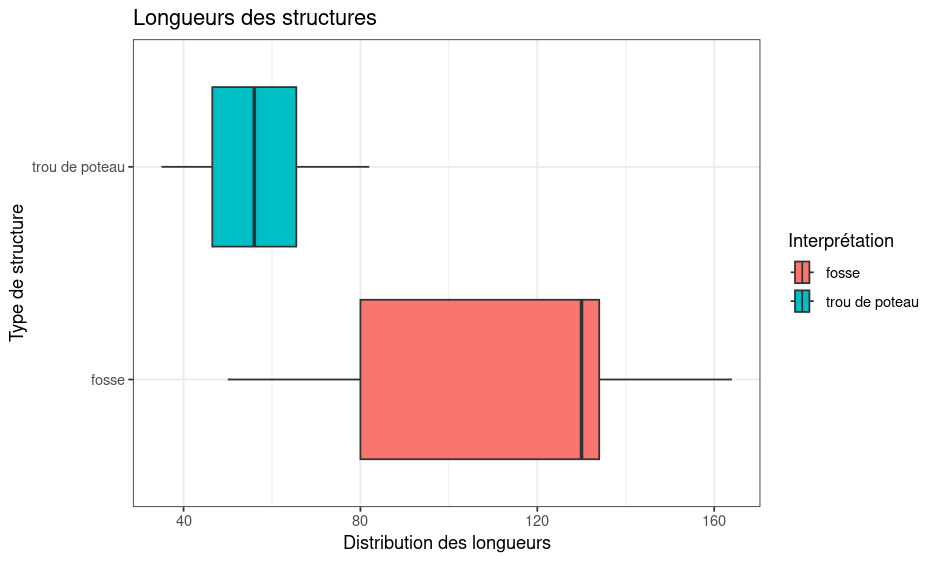
J'ai mis des beaux retours à la ligne pour tout rendre plus lisible. L'organisation de ggplot est vraiment modulable, donc on peut y aller étape par étape, en ajoutant et testant un élément à la fois. Ça permet de faire des graphiques aux petits oignons !
l'Addin Esquisse
Vous avez un addin bien pratique, installable avec le package esquisse. Globalement, ça vous permet de faire des graphiques ggplot avec une interface graphique, c'est sympa non ?
Une fois installé, vous pouvez aller le chercher dans les addins → esquisse. Comme toujours, la meilleure pratique c'est de copier le code pour le coller dans votre script de travail. Comme ça, quand vous relancez votre script, les graphiques aussi sont re-générés, c'est encore mieux ! En plus, esquisse ne propose pas toutes les options disponibles dans ggplot, c'est normal, autant le garder le plus simple possible et les petits trucs en plus  , vous pourrez les rajouter manuellement. Bon, en revanche, il faut se farcir la citation un peu niaiseuse, mais c'est un prix faible à payer vis-à-vis de ce que ce plugin vous apport !
, vous pourrez les rajouter manuellement. Bon, en revanche, il faut se farcir la citation un peu niaiseuse, mais c'est un prix faible à payer vis-à-vis de ce que ce plugin vous apport ! 
À l'ouverture du module, une première fenêtre vous propose vous aide pour l'import des données dans l'extension :
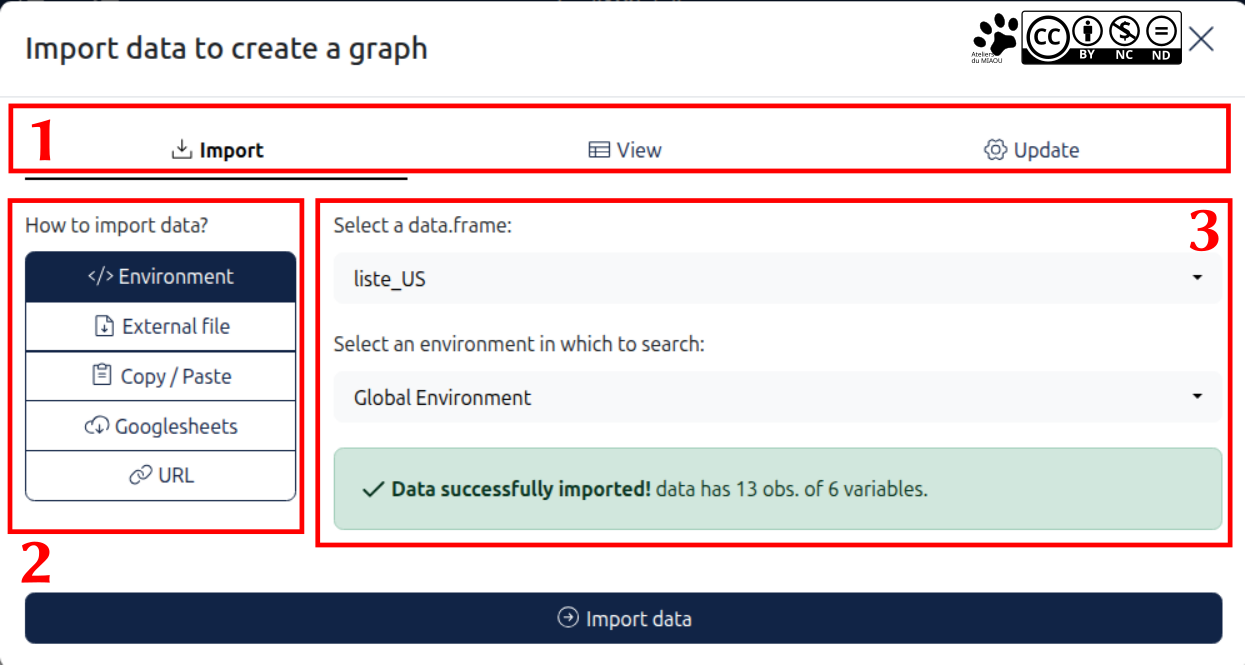
Une première barre pour choisir l'import (je reviendrai dessus dans les points 2 et 3), la vue (vous ouvez vérifier ici que vos données sont correctement importées) et "update", qui vous permet de corriger la façon dont les colonnes dont importées, comme leur type ou leur nom.
Cette partie vous permet d'importer des données depuis des emplacements différents. Comme ça, c'est très sympa, mais dans la pratique, je n'ai jamais utilisé ces options, c'est tout de même plus simple de faire des graphiques sur des données que nous sommes en train de traiter (et pas juste faire des graphiques pour faire des graphiques).
Sélection du data frame, pensez donc bien à convertir vos données en data frame ! L'environnement vous permet de charger des éléments spécifiques, je vous propose de laisser "Global Environment". Si vous avez besoin de changer cette option, c'est que vous n'avez plus du tout besoin de ce support.
Ensuite, passons à la fenêtre principale. Je vous ai encore fait une belle capture d'écran avec plein de numéros. Ce n'est pas d'une esthétique folle, c'est long à produire et il faut tout mettre à la poubelle si le logiciel change d'interface, mais c'est pratique (et je ne suis pas sûr qu'il y ait beaucoup d'autres solutions d'ailleurs) alors on y va... 
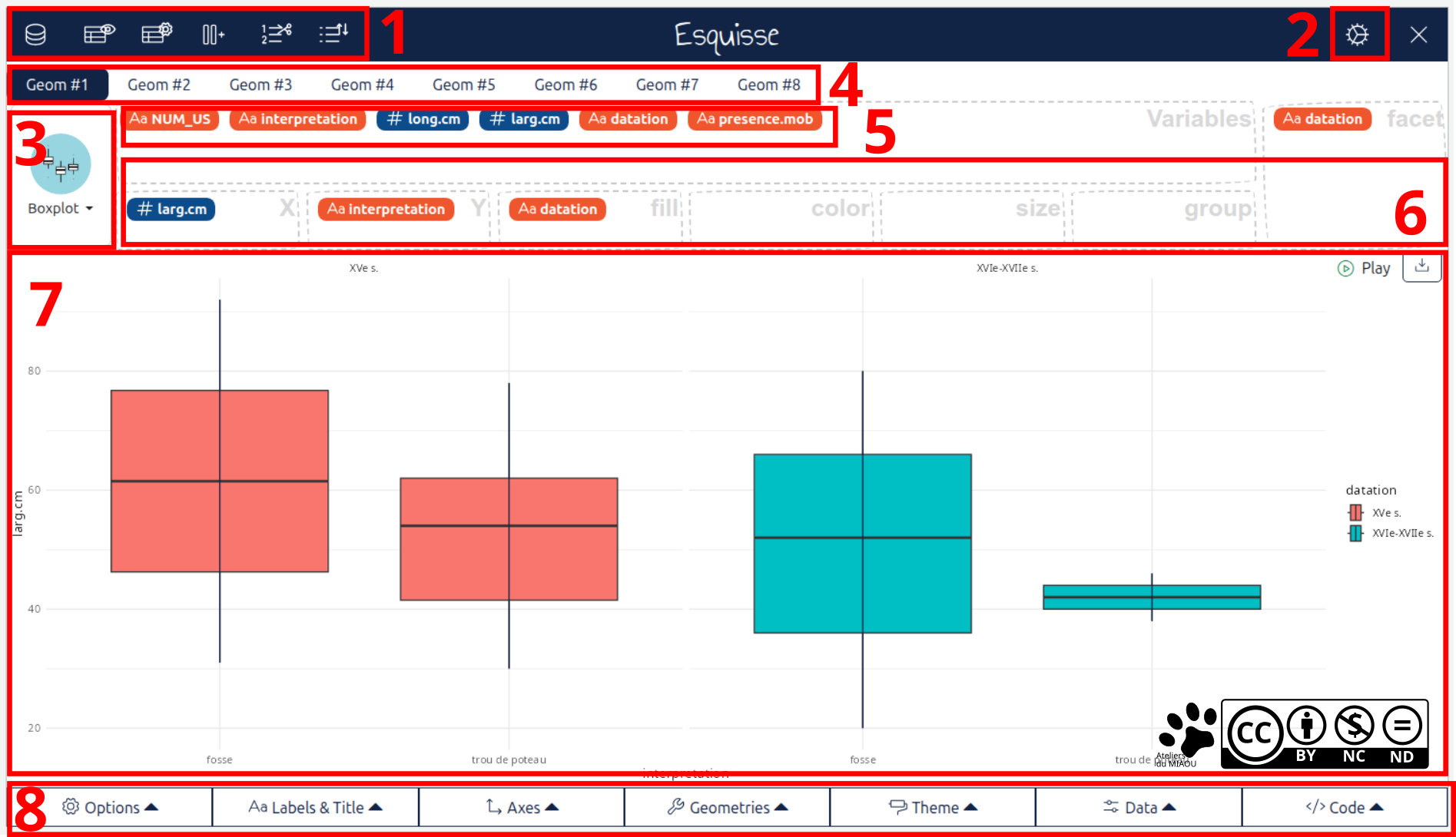
Cette partie vous permet de manipuler un peu vos données, avec notamment des outils proches de ceux de
Questionr.Je parlais plus haut des options manquantes. Il y en a pas mal que vous pouvez sélectionner ici, histoire de les ajouter à votre interface (mais allez-y doucement, on a vite fait de surcharger la fenêtre).
Sélection du type de graphique. Vous verrez qu'esquisse vous propose des types de graphiques en fonction des données que vous allez mettre en x et/ou y. Il arrive souvent que vous n'ayez pas accès à tout et vous ne pouvez pas étendre la fenêtre. C'est un problème récurrent avec les applications shiny qui ne gère pas les résolution d'écran de ouf. Dans ce cas, il faut augmenter la résolution de votre écran, juste le temps de pouvoir sélectionner ce qui vous intéresse (commencez par tester l'agrandissement qui est affiché en pourcentage, c'est le plus souvent suffisant).
Ajouter des géométries. Globalement, c'est pour faire des graphiques complexes avec plusieurs types de graphiques ensemble. C'est vraiment rare et, pour l'instant, je n'ai jamais vu de graphique vraiment réussi comme ça... (oui, les domaines qui touchent la biologie ou la physique et la chimie, je vous pointe du doigt).
Les variables issues de votre tableau de données. C'est sympa, esquisse affiche les variables numériques en bleu avec un "#" et les variables catégorielles en orange avec "Aa".
Organisation des variables dans le graphique. Il vous suffit de glisser les variables présentées au-dessus vers la destination qui vous intéresse. Il y a plein de possibilités et le plus simple, c'est d'explorer en testant, donc je ne vais pas trop insister. Un élément à noter (j'ai remarqué qu'il passait souvent à la trappe), l'emplacement "facet". C'est hyper pratique, ça vous permet de diviser votre graphique en fonction d'une variable (catégorielle normalement). Dans l'exemple ici, j'ai choisi la période. Ça donne deux graphique (en un), parfaitement alignés et à la même échelle, donc du full Bertin compatible !

Le graphique, comme ça on voit tout de suite si c'est joli (the rule of Bertin).
Des boutons d'options supplémentaires, je vous laisse explorer. Le dernier, néanmoins
 , vous affiche le code. Je vous conseille donc plutôt de le copier/coller, comme je l'ai dit plus haut, comme ça, hop on l'insère dans le script.
, vous affiche le code. Je vous conseille donc plutôt de le copier/coller, comme je l'ai dit plus haut, comme ça, hop on l'insère dans le script.
C'est quoi un bon graphique ?
J'ai mentionné ici ou là (j'ai pas mis de liens parce que je ne sais vraiment plus où et quand (enfin tant que j'arrive à rentrer chez moi, la sénilité est encore acceptable  )). Un bon graphique, comme dit l'adage (enfin moi, mais après quelques bières, ça devient un adage ancestral), doit être :
)). Un bon graphique, comme dit l'adage (enfin moi, mais après quelques bières, ça devient un adage ancestral), doit être :
- Significatif → Il doit être porteur de sens, correspondre à une problématique, à un discours défini, sinon, c'est du blabla bordélique

- Synthétique → Il ne faut présenter que les informations utiles, le reste, c'est du bruit
- Lisible → Il faut qu'il soit aéré avec une police d'écriture qui ne se brouille pas avec le graphique ou des couleurs distinguables

- Esthétique → On dirait pas forcément, mais c'est vraiment hyper important. Si c'est joli, on a envie d'y aller (pensez à éviter le rose moche ou à ajouter des chats mignons), un gateau, ça se mange d'abord avec les yeux

Une référence pour les gouverner tous, Sémiologie graphique: Les diagrammes, les réseaux, les cartes de Jacques Bertin (première édition de 1967). Vous y trouverez un ensemble de règles, basées pour l'essentiel sur des retours d'expérience, qui, si vous les suivez, vous ferons produire des graphiques d'exception ! Je vous recommande cet excellent billet du blog visionscarto écrit par Gilles Paslky, qui expose parfaitement le contexte et l'impact de cet ouvrage majeur (oui, je ne mâche pas mes mots).
Ressources supplémentaires pour faire des graphiques
R Graph gallery, https://r-graph-gallery.com/. Plein d'exemples basés sur des bibliothèques différentes. À chaque fois, vous avez le code pour réaliser vous-même.
La cheat sheet. On l'a déjà dit, c'est pas vraiment un modèle de lisibilité, mais ça vous guidera quand même. Pour y accéder dans R Studio : "Help" → "Cheat Sheets" → "Data Visualization with ggplot2".